Dubbing and Voice-Over: Cloning and Directing a Voice for Your Film
A complete method of dubbing and voice-over with AI to clone, direct and mix a credible voice, with no robotic render or audio artifacts.

You wrote a great scene. The frame is clean. The light already tells something. Then you lay an AI voice on it and everything collapses in ten seconds. It sounds clean, but dead. It is the most frequent mistake among beginners: believing that a good voice cloning tool replaces acting direction.
I am going to be frank. AI dubbing and voice-over are not a magic button. It is a discipline. You must direct a performance, breathe the text, control the rhythm, and mix the voice like a scene element. Otherwise you get that "generic podcast" texture that ruins the credibility of a film, even when the image is gorgeous.
The good news is that you can learn fast. In this guide, I give you the pipeline I use in production: preparation of the source voice, generation by intention blocks, fine direction of the interpretation, clean lip sync, then audio integration at a pro deliverable level. The goal is not just to hear words. The goal is to make people believe that someone really lives the scene.
Core concepts: what makes an AI voice credible on screen
A convincing AI voice rests on three pillars. The timbre, the intention, and the sound context. Beginners focus on the timbre and neglect the rest. Result, the voice "resembles" the right person but "plays" nothing. For a viewer, it is immediately perceptible, even if they cannot explain it technically.
The second pillar is the prosody. It is the music of the sentence: pauses, accelerations, consonant attacks, breaths. A correct sentence on paper can become false to the ear if its internal movement is not mastered. In a film, the audience reads the emotion through these micro-variations. If you lose them, you lose the scene.
The third pillar is the acoustic integration. A voice must belong to its set. A line in a tiled kitchen does not have the same density as an interior voice murmured in a tight shot. Many AI renders fail here: the text is clear, but floats above the image like a layer stuck on afterward.
When I train beginner creators, I repeat a simple sentence to them: "A credible AI voice is acting direction applied to audio." You guide a performance, you do not validate a file. This posture changes everything in your way of working, and it is precisely what gets you out of the standardized render.
If you want to reinforce this logic on the visual narration side even before the sound design, I advise our guide to creating a visual narration with no dialogue. You will better understand how the voice must complete the image, not crush it.
| Use | Goal | Key settings | Frequent mistake | Quick fix |
|---|---|---|---|---|
| Advertising voice-over | Clarity + fast impact | Dynamic pace, light compression, clean articulation | Voice too "radio announcer" | Add a scene intention + natural pauses |
| Fiction dubbing | Emotional immersion | Micro-intensity variation, controlled breaths, coherent room tone | Diction too smooth | Rewrite the acting punctuation + short takes |
| Documentary narration | Credibility + consistency | Steady tone, clear mid EQ, controlled sibilance | Monotony over 3+ minutes | Segment into intention chapters |
| Training avatar | Continuous intelligibility | Stable pace, clean consonants, moderate de-esser | Robotic render | Inject fine rhythm variations |
The trench workflow: a field pipeline to clone and direct an AI voice
Before any generation, you must secure the source material. Even if the tool promises a clone "from 10 seconds", do not work blind. Prepare 2 to 5 minutes of clean voice, in varied intentions, with a constant mic and a stable level. The algorithm learns a living actor better than a perfect but monotonous sample.
Then, cut your script into dramatic blocks, not into visual paragraphs. One block = one clear intention. Example: restraint, tension, fragility, affirmation. This segmentation avoids the uniform monologues that sound false. In practice, I rarely generate more than 1 to 3 sentences per pass to keep a fine artistic control.
At this stage, think about your image. A too-active voice can destroy a contemplative shot. A too-slow voice can break a tension scene. You must read the voice with the edit, not on headphones in solo. For that, I always open the timeline, even in a draft version, and I test the lines in the real flow.
Last basic rule: keep a log of the prompts and acting settings. You note each pass, what works, what sounds artificial, what holds at the mix. In two projects, you build your own dictionary of intentions. That is where you move from "I test presets" to "I direct a performance".
Step 1: prepare a usable source voice, not just a clean one
Start by recording a vocal base with silence at the start and end, at a fixed mic distance. The goal is not to make a final performance. The goal is to capture the vocal signature with no acoustic pollution. If your space is imperfect, prefer a coherent and controlled take to an "ultra-silent" take cobbled together with destructive plugins.
Make the voice speak in several emotional colors. A neutral version, a more tense version, a more intimate version. Many beginners give a single tone to the machine and are surprised to get flat outputs. The model clones what you give it. If the input is mono-intentional, the output will be mechanically monotonous.
Also prepare the text for the synthesis, not only for human reading. Add acting punctuation. Commas to breathe, short periods to cut the momentum, ellipses when the breath must stay open. It radically changes the musicality without touching the underlying sentence.
Before validating, listen to the source in context headphones + simple speakers. You must detect the aggressive sibilants, the plosives, and the level instabilities. It is a basic check, but it spares you errors that multiply after cloning.
Step 2: generate by intention blocks with explicit direction
You are going to generate each block like a mini scene. Do not write just "natural voice". Give a usable acting instruction: "restrained but firm", "tired without being apathetic", "urgent without screaming". A vague direction creates a standard voice. An embodied direction creates a credible voice.
Keep short segments. I recommend 8 to 20 seconds maximum for the first passes. Beyond that, you lose control over the micro-inflections. Yes, it multiplies the exports, but the quality climbs immediately. In film audio, precision always beats raw speed.
Make at least three variants per block. Variant A safe, variant B more emotional, variant C more restrained. Then, place them all in the timeline and choose with the image. You will often see that a less demonstrative version gains in truth at the edit.
Name your files intelligently: sc03_bl02_tension_B_v2.wav. This system seems trivial. In reality, it lets you come back fast to an intention that worked, without losing an hour re-listening to twenty anonymous exports.

💡 Frank's Cut: when a line sounds artificial, lower the level of requested emotion. The AI overacts easily. An intention at 70 percent often seems more human than an intention at 100 percent.
Step 3: align dubbing and lip sync without killing the acting
Lip sync is a classic trap. Many look for the perfect alignment to the frame and destroy the interpretation. In real life, speech is organic. There are natural micro-offsets. If you correct everything surgically, you get a correct mouth and a dead emotion.
Start by locking the attack consonants on the major lip openings. It is what the eye catches first. Then, adjust the long vowels and the sentence ends. Do not try to constrain each phoneme. You want a credible illusion, not a technical demonstration.
If you work with an avatar or a generated actor, anticipate the engine's limits. Some fast syllables pass badly. Then rewrite the sentence to keep the meaning with a more stable articulation. It is not cheating. It is direction.
When you doubt, cut short and regenerate the line. Many beginners spend 40 minutes micro-editing a mediocre take. In production, redoing a clean pass in 5 minutes is often more profitable and higher quality.
Step 4: mix the voice so it really belongs to the scene
A clean voice is not an integrated voice. For it to live in the shot, work your EQ minimally but in a targeted way. Lighten the muddy lows, clarify the mids useful to intelligibility, and calm the aggressive highs without smothering the air. Each scene demands a different balance.
Compression then, but with restraint. You want to stabilize the diction, not crush the emotional dynamics. A too-compressed voice becomes flat, tiring, and artificially "broadcast". In fiction, it is often the breathing of the micro-variations that carries the truth of the acting.
Add a reverb consistent with the set, very discreet. A small room, a hallway, a wet urban exterior, these are not the same signatures. If your reverb is audible as an effect, it is often already too much. The viewer must not hear the plugin. They must believe the place.
Finalize with a context check. Test the voice with the music, the ambiences, and the effects. A superb solo voice can disappear under a dense sound design. I recommend checking the readability on a phone and a laptop, not only in studio monitoring.
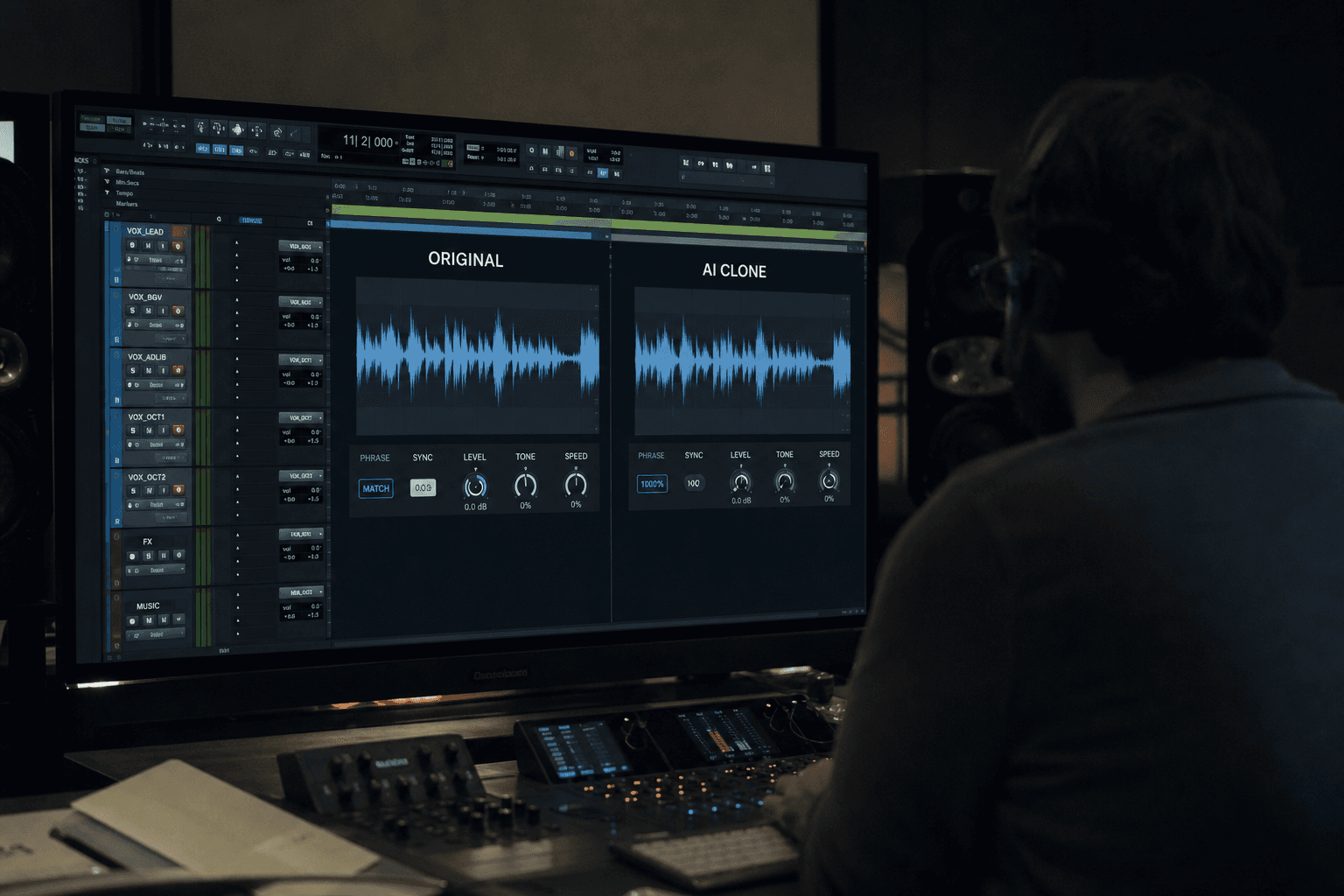
Troubleshooting: what beginners break in AI dubbing and how to fix it
First massive problem, the monotony. You generate a long text in one pass and the whole voice keeps the same energy. The correction is immediate: segment into intention blocks and reinject rhythm variations. Even a light pace variation between two sentences can be enough to make the performance credible.
Second break, the aggressive sibilants and percussive consonants. It often happens when you push the clarity too much in post. Solution: moderate de-esser, transient control, and a better-calibrated source diction. Do not try to correct at the mix only what is already imbalanced in the generation.
Third frequent mistake, the voice detached from the set. It is clean, but floats. To fix, lay a coherent room tone, adjust the reverb according to the visual space, then realign the voice level in the global dynamics of the scene. The acoustic integration is worth as much as the quality of the timbre.
Fourth problem, rigid lip sync. The words stick but the performance seems mechanical. Here, you must accept a slight natural offset, rework the intention, and sometimes simplify the sentence. The audience forgives a micro lip imperfection. It does not forgive a false emotion.
Fifth trap, wanting to clone a celebrity or an identifiable voice with no legal frame. It is a legal bomb for a pro project. Use authorized voices, document your rights, and maintain a clear traceability of the audio sources. If you monetize your content, this discipline is non-negotiable.
To go deeper into the legal and commercial part around AI production, you can read our guide on selling AI videos to professional clients. And if you want to structure your complete project from the scene to the final render, pick up our complete workflow from an idea to a realistic AI film.
💡 Frank's Cut: in case of artistic doubt, always choose the take that serves the character rather than the technically "cleanest" take. A film is won on the emotion, not on the clinical perfection.
Solid external references to progress with no noise
Avoid building your workflow on viral excerpts with no method. To understand the technical bases of level and loudness, the EBU R128 recommendation stays a serious reference. For broader broadcast standards, the ITU-R BS.1770 recommendations give a useful frame. On the editing and post-production side, the DaVinci Resolve Fairlight documentation helps to structure a clean audio chain.
"The real test of an AI voice is not knowing whether it impresses in solo. It is seeing whether it disappears into the story."
FAQ: the real questions before cloning a voice for a film
-
How many minutes of source voice do you need for a really credible clone?
In practice, I recommend at minimum 2 to 5 minutes of clean voice, with several acting intentions. Yes, some tools announce results with a few seconds, but the emotional stability and the prosodic consistency are often weak. The more your corpus is diverse and controlled, the more you get a usable voice in production. Better 3 well-recorded minutes with natural variations than a long monotonous recording. Think material quality, not raw volume. It is this base that conditions all the rest of the pipeline. -
What is the difference between AI voice-over and AI dubbing?
AI voice-over comments or guides, often off-screen, with a priority demand for clarity. AI dubbing, on the other hand, must align with the visual performance of a character and respect the rhythm of the lips, the breaths, and the dramatic intentions. In voice-over, a slight stylization can work. In fiction dubbing, this stylization quickly becomes artificial if it is not anchored in the acting. The two disciplines use close tools, but the validation criteria are different. Mixing the two approaches is a frequent source of inconsistent render. -
How to avoid the cloned voice sounding robotic even with a good model?
The robotic render rarely comes from a single parameter. It comes from a combo: text too literal, absence of acting punctuation, generation of too-long blocks, and excessive compression at the mix. To correct, segment your sentences, write intentional breaths, and direct the performance with concrete instructions. Then, keep a natural dynamic in post-production. A too-leveled voice loses its humanity. Finally, always validate with the image: what seems neutral in solo can become false in a scene context. -
Should you write the script differently for AI voice synthesis?
Yes, clearly. A script intended for silent human reading is not always suitable for synthesis. You must clarify the breaks, simplify certain formulations, and add punctuation that guides the intonation. It does not mean impoverishing your text. It means writing for the ear, not only for the eyes. I advise rereading each line aloud and adjusting until you feel a natural rhythm. This editorial work upstream strongly reduces the retakes and improves the final credibility. -
How to integrate the AI voice with the music without losing intelligibility?
The key is the frequency and dynamic balance. If the music occupies the mids where the voice lives, you lose the comprehension, even at a correct volume. Start by clarifying the voice with a light EQ, then create space in the music, often via a targeted attenuation around the critical zones of the diction. Then, adjust the compression musically, not aggressively. Finally, test on varied systems. A voice readable at the studio can become drowned on a smartphone. The multi-support control stays indispensable. -
Does the lip sync have to be perfectly aligned to seem real?
Not necessarily. What seems real is a credible alignment of the key moments, especially the consonant attacks and the marked mouth openings. Wanting to align each phoneme surgically can produce a rigid and artificial result. Better to aim for a living synchronization than a mechanical lock. In a real human performance, micro-offsets exist. The viewer accepts them. What they refuse is a perfect mouth with an absent emotion. Always prioritize the dramatic intention before the obsessive precision. -
Which legal risks should you anticipate before publishing a cloned voice?
You must secure the rights of the source voice, check the usage conditions of the tool, and document the consents if a real voice is involved. Publishing or selling content with a cloned voice with no clear frame can lead to serious litigation, even if the technical quality is excellent. In a pro context, keep a trace of your licenses, tool versions, and source files. This rigor protects your activity and reassures the clients. The legal is not an administrative detail, it is a part of the global quality of the project. -
What fast protocol to apply when you start and want a clean result in one session?
Do a structured 90-minute sprint. 20 minutes of source voice preparation and punctuated script, 35 minutes of generation in blocks with three variants per key line, 20 minutes of timeline integration and lip sync, then 15 minutes of basic mixing and multi-support check. At the end, keep a "safe" publishable version and an "ambitious" version for a test. This frame prevents you from going in circles. It creates clean, measurable decisions, and makes you progress project after project.